Pro-Pose: Unpaired Full-Body Portrait Synthesis via Canonical UV Maps

Abstract
Photographs of people taken by professional photographers typically present the person in beautiful lighting, with an interesting pose, and flattering quality. This is unlike common photos people can take of themselves. In this paper, we explore how to create a "professional" version of a person's photograph, i.e., in a chosen pose, in a simple environment, with good lighting, and standard black top/bottom clothing. A key challenge is to preserve the person's unique identity, face and body features while transforming the photo. If there would exist a large paired dataset of the same person photographed both “in the wild” and by a professional photographer, the problem would potentially be easier to solve. However, such data does not exist, especially for a large variety of identities.
To that end, we propose two key insights: 1) Our method transforms the input photo and person’s face to a canonical UV space, which is further coupled with Donor-based UV Reposing to model occlusions and novel view synthesis. Operating in UV space allows us to leverage existing unpaired datasets. 2) We personalize the output photo via multi-image finetuning. Our approach yields high-quality, reposed portraits and achieves strong qualitative and quantitative performance on real-world imagery.
Results
We compare our method against state-of-the-art baselines including Gemini 2.5 Flash Image on both in-domain (DeepFashion) and out-of-domain (WPose) datasets. All Pro-Pose results are zero-shot (without test-time fine-tuning).
Qualitative results demonstrating the effectiveness of Pro-Pose on real-world imagery.
Navigate: Use arrows or click side cards to browse samples. Compare: The output column cycles through models automatically.
Stratified Identity Analysis
Among the metrics above, FaceSim (face similarity) is arguably the most perceptually important — it measures how well a method preserves a person's identity after reposing. To quantify identity robustness under varying difficulty, we stratify FaceSim scores on the WPose (out-of-domain) test set by the magnitude of head-pose change between source and target (measured as the L2 distance of Euler-angle differences).
Identity Preservation vs. Pose Difficulty. FaceSim scores stratified by pose-change magnitude. Pro-Pose closely tracks Ground Truth identity variance across all difficulty bins, while baselines degrade rapidly. With identity breakage defined as FaceSim < 0.4, Pro-Pose fails in only 13.5% of cases vs. > 97% for all baselines.
As the plot shows, Pro-Pose closely tracks the inherent identity variance of Ground Truth images across all pose-change bins, whereas all baselines exhibit rapid degradation as pose difficulty increases. Defining identity breakage as a FaceSim score below 0.4, Pro-Pose exhibits a failure rate of only 13.5%, while all competing methods (LEFFA, MCLD, UniHuman, OnePoseTrans) fail to preserve identity in over 97% of generated samples.
Method
Overview: We address the challenge of synthesizing highly realistic and pose-controllable human avatars by proposing a unified framework capable of learning from both abundant single-view images and scarce paired data. This integration is achieved through a novel supervision strategy formulated directly in canonical UV texture space, which naturally disentangles pose from appearance.
Overview of our Avatar Generation Framework. Our approach leverages single-view datasets by operating in a canonical UV space, extracting UV texture and pose. Left (Paired Supervision): When ground-truth pose pairs are available, we condition the Flow Matching model on the partial UV texture, target pose, and face crop. Right (Single-View Self-Supervision): To prevent "pose leakage" from occlusion boundaries when training on single images, we introduce a Donor-based UV Reposing module. This synthetically re-poses the input texture using a random donor visibility mask, forcing the model to learn robust identity representations. Furthermore, we drop out the face crop condition in this branch to prevent trivial reconstruction via pixel-perfect information leakage.
Donor-based UV Reposing: To mitigate pose leakage where the network learns shortcuts from occlusion boundaries, we introduce Donor-based UV Reposing. We mask the input texture using a visibility mask extracted from a randomly selected ‘donor’ image. This breaks the correlation between input texture boundaries and the target pose, forcing the generator to recover the original view through robust geometric inpainting.
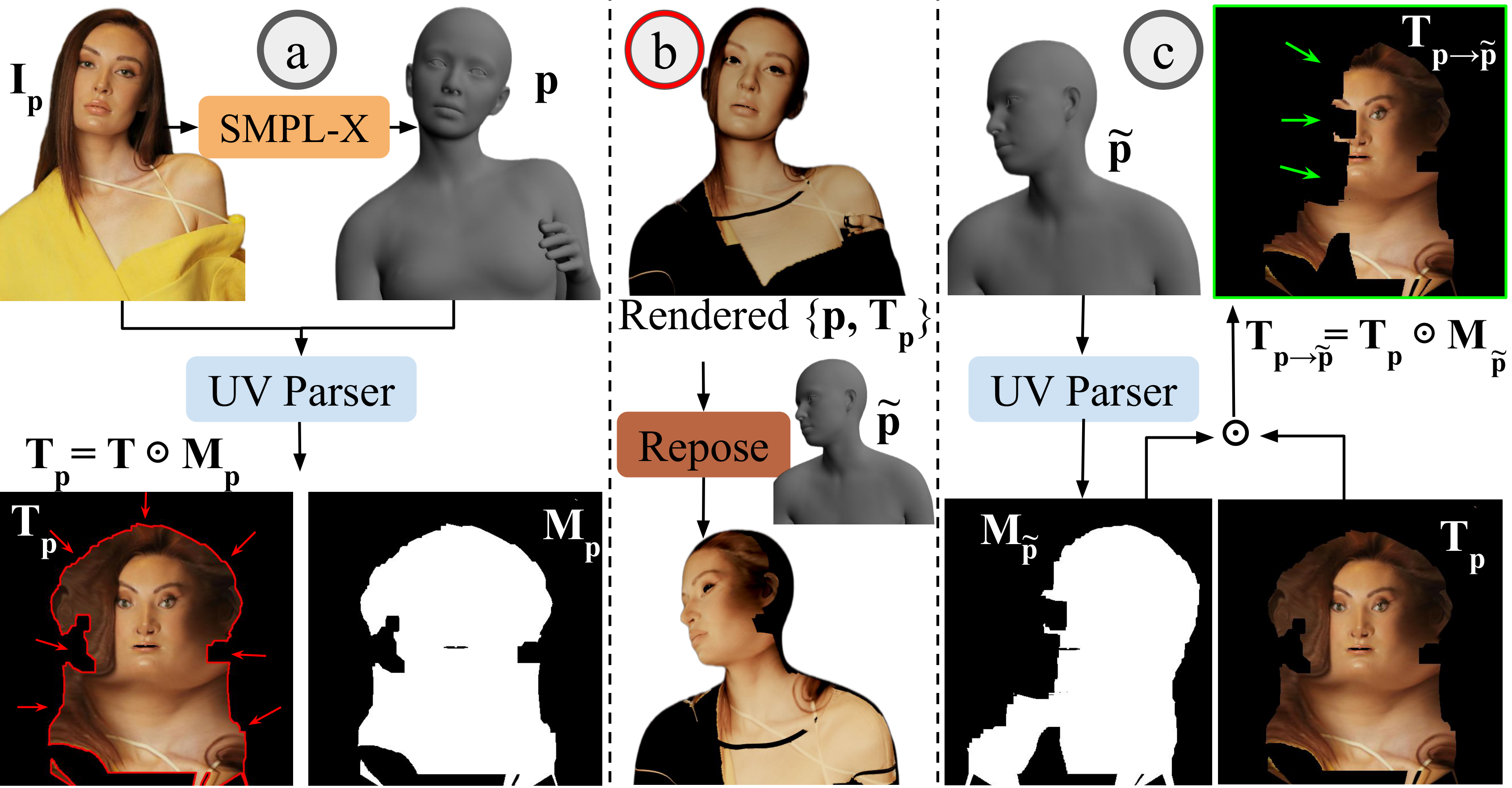
Pose Leakage Mitigation. (a) Standard partial textures Tp leak source pose information via occlusion boundaries, allowing trivial reconstruction shortcuts. (b) Generating pseudo-pairs via image-space rendering is computationally prohibitive for online training. Moreover, SMPL-X lacks fine details — such as hair — leading to unrealistic renderings. (c) Our Donor-based Reposing efficiently bypasses rendering by applying random donor masks Mp̃ directly in UV space. This simulates novel occlusions, preventing leakage and forcing the network to learn robust geometric warping. Note: To clearly visualize the subtle boundary differences (indicated by arrows), here we display a crop of just the face region from the full texture map; in practice, donor-reposing applies to all body parts.
Base Clothing Dataset: We utilize paired data from DeepFashion, unpaired single images from FFHQ, and commercial data derived from e-commerce websites. To ensure visual uniformity across these diverse sources, we generate the Base Clothing (BC) dataset using an identity-preserving I2I model (Gemini 2.5 Flash Image), standardizing subjects into black tank tops and shorts without altering their identity or pose.

Base Clothing (BC) Standardization. We apply different preprocessing strategies based on the data. For DeepFashion and Commerce images, we generate the base garment while preserving pose and identity via pixel-aligned editing (Prompt V1). For FFHQ, we use generative outpainting to expand limited face crops into full-body samples (Prompt V2).
Analysis of Identity Overfitting
Visual Confirmation of Identity Overfitting
Our graph-based clustering analysis confirmed that DeepFashion is dominated by a small number of professional models (~100 clusters). This lack of diversity leads to severe overfitting in paired-only models. As shown below, this bias is so strong that the model frequently collapses to a dominant training identity (highlighted in red), even overriding semantic cues like gender.


(a) Top 100 identity clusters in DeepFashion, with the dominant identity highlighted. (b) Qualitative comparison showing how the Paired-Only model (middle column) often collapses to the specific male face highlighted on the left (e.g., row 2), whereas our full model (right column) preserves the correct identity.
Identity Analysis of Generated Images
A primary motivation for our work is the limited identity diversity in existing paired datasets like DeepFashion, which contains only about 100 unique identities. To diagnose the impact of this, we compared the face similarity between generated outputs and the training set. We found that models trained exclusively on paired data (shown in red) exhibit high similarity to the training samples, indicating a tendency to memorize and "pull" novel identities toward the few known training subjects. In contrast, our full model (shown in blue), which leverages abundant unpaired data, maintains lower similarity to the training set, demonstrating significantly better generalization to unseen identities.
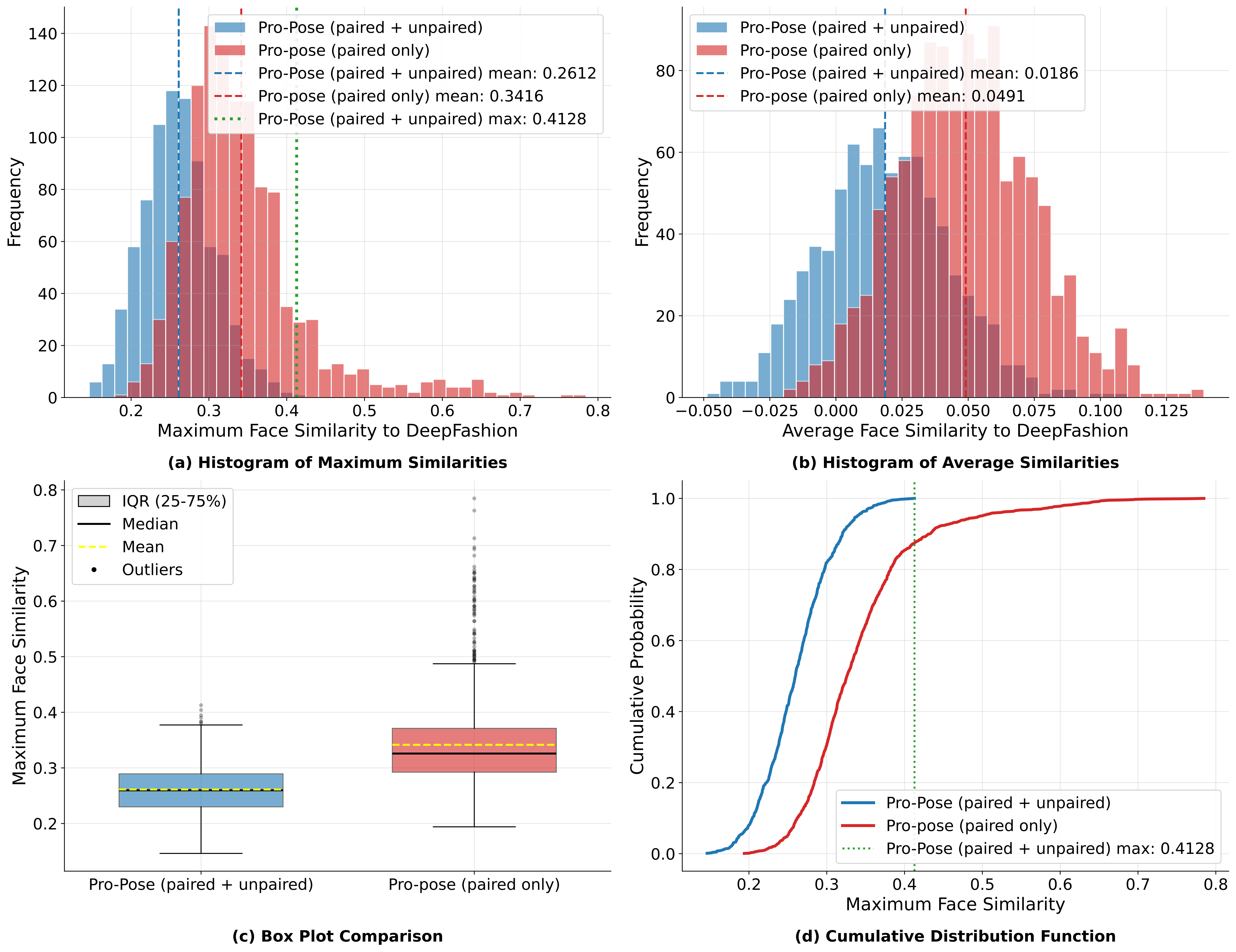
Diagnosing Identity Overfitting via Cross-Dataset Generation. We evaluate the extent of identity overfitting by comparing the face similarity between images generated on the out-of-distribution WPose dataset and the identities present in the DeepFashion training set. Two Pro-Pose models are tested: Pro-Pose (paired only), trained on limited DeepFashion paired data, and Pro-Pose (unpaired + paired), trained on abundant unpaired data plus the limited paired data. The Pro-Pose (paired only) model exhibits a significantly higher face similarity to the DeepFashion training identities when reposing WPose identities. This result acts as a diagnostic, demonstrating that the paired-only model has overfit to the limited DeepFashion identities, causing it to generate new faces that are biased towards its training set, whereas the combined training approach ensures better generalization.